代码节点
节点说明
代码节点用于在AI工作流中执行自定义Python代码,实现数据转换、结构化处理、数学计算、数据拼接等任务。该节点极大增强了开发人员的灵活性,允许他们嵌入自定义脚本,以处理节点间的数据交互。
节点配置
代码节点包括以下模块配置:输入、代码和输出。
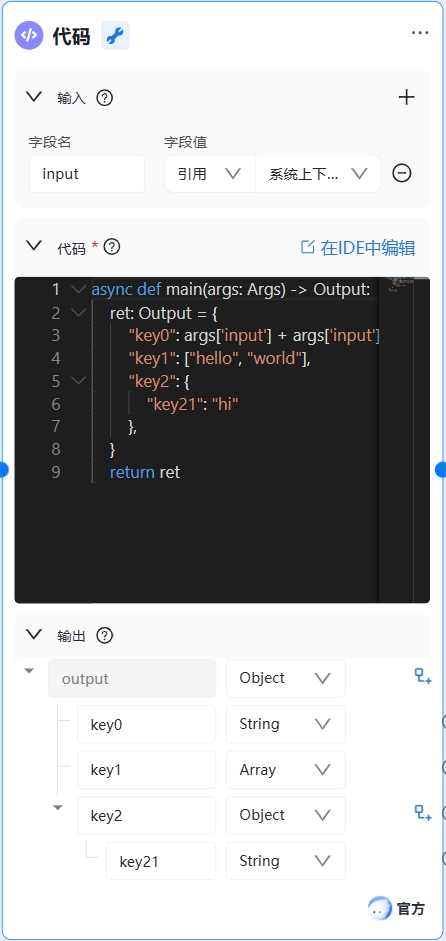
输入模块
输入模块用于定义并引用其他节点提供的数据。在代码节点中使用其他节点的数据,需在输入中定义这些变量。
代码模块
在代码模块中,您需要编写一个函数结构,直接使用输入参数中的变量,并通过return返回一个对象、数组或其他基本类型的数据作为输出结果。
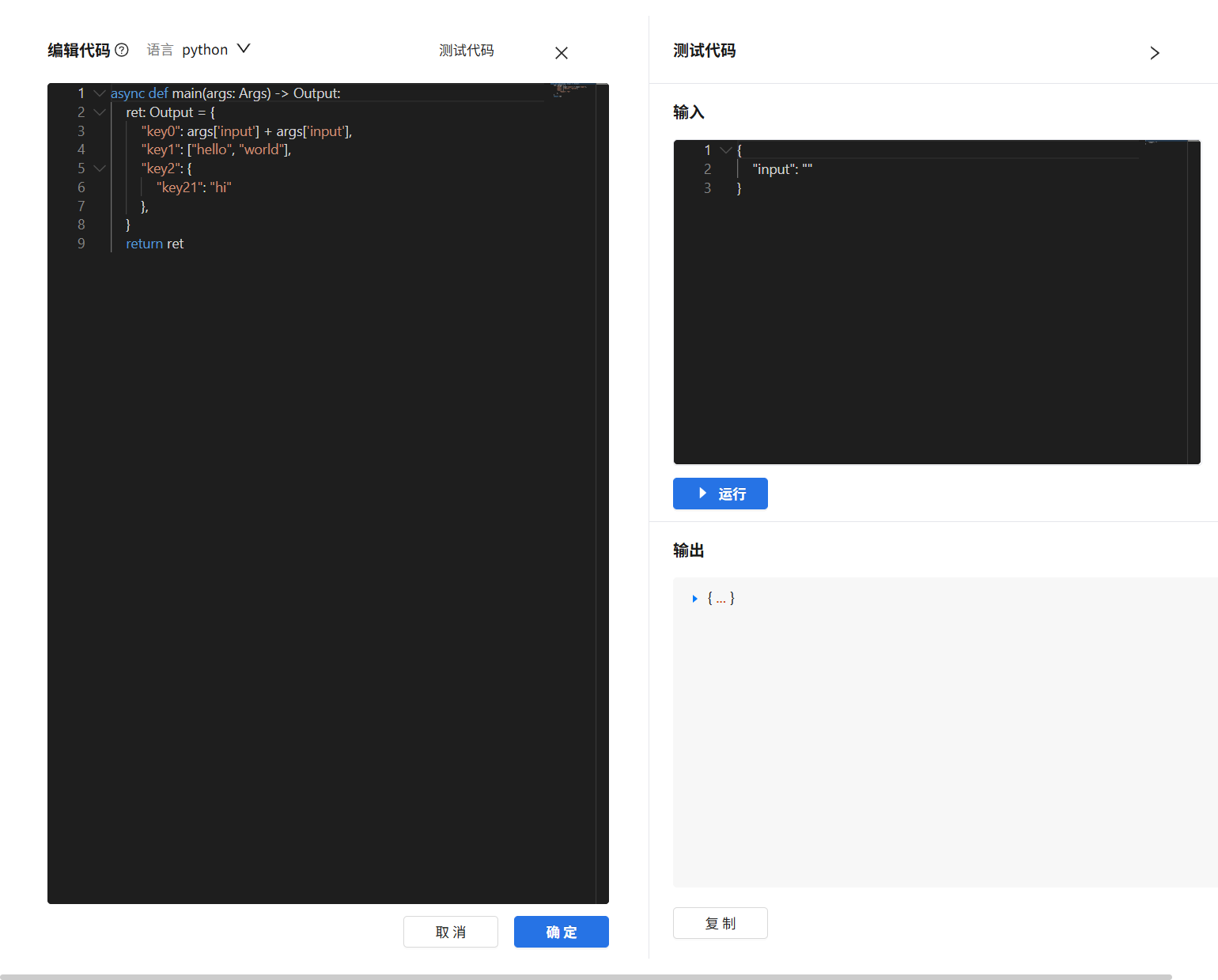
- 可点击”在IDEA中编辑”按钮,打开代码编辑界面。
- 在代码编辑界面编写代码后,点击右上角的”测试代码”进入调试界面。
- 在调试界面中输入入参,点击”运行”按钮即可在输出中查看执行结果。
输出模块
输出模块定义代码运行完成后输出的变量,必须确保此处定义的变量名、变量类型与代码中return返回的对象完全一致。
常见使用场景
代码节点主要用于以下场景:
1. 结构化数据处理
常用于处理非结构化数据,如JSON字符串的解析、提取与转换。例如,从HTTP节点返回的数据中提取特定字段:
import json
async def main(args: Args) -> Output:
data = json.loads(args['http_response'])
ret: Output = {
'result': data['data']['name']
}
return ret
注意:
http_response为输入变量名。
2. 数学计算
执行复杂的数学计算或统计分析。例如计算数组的平方差:
async def main(args: Args) -> Output:
x: list = args['num_list']
mean = sum(x) / len(x)
ret: Output = {
'result': sum([(i - mean) ** 2 for i in x]) / len(x)
}
return ret
注意:
num_list为输入变量名。
3. 数据拼接
合并多个数据源的数据,如知识检索结果或API调用结果。例如合并两个知识库的数据:
async def main(args: Args) -> Output:
knowledge1: list = args['knowledge1']
knowledge2: list = args['knowledge2']
ret: Output = {
'result': knowledge1 + knowledge2
}
return ret
注意:
knowledge1与knowledge2为输入变量名。
安全策略
代码节点运行环境经过严格沙箱隔离,禁止执行消耗大量系统资源或具有安全风险的操作(如直接访问文件系统、网络请求、系统命令等)。
代码节点已预置黑白名单,限制可用的第三方及内置Python包。
-
白名单:
['asyncio', 'json', 'typing', 'pandas', 'numpy', 're', 'requests', 'httpx', 'datetime', 'time', 'base64', 'hashlib'] -
黑名单:
['os', 'sys', 'cmd', 'subprocess', 'multiprocessing', 'timeit', 'platform']
常见问题
- 如何引用前置节点的数据?
- 在
输入变量中定义变量名,并在代码中通过args['变量名']引用。
- 为什么我的代码无法执行?
- 确认代码未使用黑名单内的库或函数,且所有引用的变量均已正确定义。
- 如何确保代码安全运行?
- 代码节点的执行环境已沙箱隔离,避免使用不在白名单内的功能,严格遵守安全策略要求。